Preemption Design
Introduction
This design is created to replace the preemption code that has been part of YuniKorn for a long time.
The original code was never fully tested. After the core cache removal as part of YUNIKORN-317 the preemption code was taken out of the scheduling path. The only changes that have gone into the preemption code were compilation fixes. As part of the preparation for the new preemption design the old code was removed in YUNIKORN-1269.
Preemption of workloads is a feature used by almost all schedulers to help critical workloads run. The criticality can be based on the fact that the system cannot work without it, i.e. DaemonSets on K8s, or based on some other factors like SLA or priority. Preemption for DaemonSet pods was implemented as part of YUNIKORN-1085. This design thus focuses on preemption for all other workloads.
Goals
- Re-use existing Kubernetes objects
- Implement inter-queue preemption
- Priority knowledge inside the core scheduler to support preemption
Non Goals
- Intra-queue preemption
- Cross node preemption
- Full priority support
Preemption and Priorities
Kubernetes
All pods for the entire cluster, across namespaces, are sorted based on priority for scheduling. A higher-priority will get scheduled before a lower-priority pod. Preemption within the Kubernetes scheduler is also based solely on the priority of the pod that is being scheduled. The full documentation can be found here.
The simple rule that governs both scheduling order and preemption behavior is that a pod with a higher priority is more important than a pod with a lower priority. This crosses namespaces. There are no boundaries or limitations that can be set. Pods from a namespace with a higher priority are scheduled earlier and could trigger the preemption of a pod from another namespace.
Priority of a pod is defined in the pod specification. Priority is a number, but is referenced in the pod specification via a PriorityClass object. The object defines a named priority and maps it to a value. In more recent versions (Kubernetes 1.24 and later), the PriorityClass can also contain a preemption policy for the scheduling phase. This preemptionPolicy only allows the pod to opt-out from preempting other lower priority pods during the scheduling phase. It cannot, and is not designed to, alter preemption behavior while the pod is running.
The same pod priority is also used during the pod eviction by the kubelet on the node. For example, if the node has been overloaded and runs out of memory or CPU, the node can evict pods. These evictions help to keep the node stable. Pods considered for eviction are ranked on priority among some other factors.
YuniKorn
The behavior in Kubernetes is all focused on the scheduling cycle. When looking at preemption from the standpoint of a batch or data processing workload, we need to take into account the possibility to opt-out while running. This option does not exist in the current configuration for workloads.
The simple approach for preemption fits in with the service type workloads that Kubernetes is designed for. Services handle the scale up and or scale down that could be triggered by preempting one of the pods for that service.
This is not the case when we look at a Spark job as an example. The driver pod is the manager of the other pods that belong to the same job. When the driver gets preempted the whole job is impacted. Preempting a driver has a follow-on effect that could cause multiple pods to be removed from the cluster. For a large job that could mean hundreds of pods. The impact is far larger than a single pod. Preempting a manager or originator pod should be prevented as much as possible.
The other case which we need to account for is an interactive session that runs on the cluster. This interactive session, like a python notebook, is a one-off instance and restarts have a wider impact. Preempting an instance like a notebook is not a desirable outcome either.
Building in all the smarts to know which pods to avoid is difficult, or even impossible. For all these cases the option to allow a “do not preempt me” flag on the pod would be required. The design will discuss this option in the Pod specification.
Priority limitations
PriorityClass objects which define the priority in a Kubernetes cluster are cluster-wide objects. The cluster administrator defines the objects and thus the supported priorities.
There are no limitations on the priority that can be set on a pod. When a pod is submitted the only check performed is that the PriorityClass specified as part of the pod specification is defined. Any rogue user can create a pod with the highest defined priority.
Limiting priorities is possible but requires an API server flag which is difficult to support in public cloud environments. We cannot rely on the option to be available in a cluster scheduled by YuniKorn.
The Laws of Preemption
Prior knowledge of implementing preemption in the Apache YARN scheduler has been used to create this design. It forms the basis for the "laws of preemption". These laws, or rules, describe overall preemption behavior.
Preemption for YuniKorn is based on the hierarchical queue model and guaranteed resources assigned to a queue.
Preemption is used to get the usage of a queue to at least its guaranteed resource capacity. It cannot guarantee that every queue will get its guaranteed resource capacity. There are cases that make it impossible to get to that state. Preemption therefore does not guarantee a final optimal state can or will be reached. The end state of the queues will normally thus be a usage that is approximately the guaranteed resource capacity.
An example case that makes it impossible to reach the optimal state is when the sum of the guaranteed resources for a group of queues is larger than the current resources available in the cluster. It is impossible to get all queues their guaranteed resources. More cases like this exist in a hierarchy with maximum quotas set at a certain point in the hierarchy preventing the optimal state from being reached.
First an overview of the laws, then the explanation and rationale behind each of the rules:
- Preemption policies are strong suggestions, not guarantees
- Preemption can never leave a queue lower than its guaranteed capacity
- A task cannot preempt other tasks in the same application
- A task cannot trigger preemption unless its queue is under its guaranteed capacity
- A task cannot be preempted unless its queue is over its guaranteed capacity
- A task can only preempt a task with lower or equal priority
- A task cannot preempt tasks outside its preemption fence (one-way constraint)
Most of the rules given around tasks and queues are there to prevent a preemption storm or loop. Preempting a task that could trigger a follow-up preemption should be avoided. The rule described should warrant against that. Breaking the rules could lead to unpredictable behavior either during scheduling or application runs.
Preemption policies are strong suggestions, not guarantees
A pod is able to request not to be preempted. However, this is not a guarantee. There could be circumstances that the scheduler might still preempt the pod. This will be a last resort action if no other solution is available. This means that the preemption policy is a strong suggestion, not a guarantee.
The example use case that could break the rule and preempt a pod that opted out of preemption is the DaemonSet case. The DaemonSet pod must run on the specified node. If all pods that are running on that node are either other DaemonSet pods or pods that have opted out of preemption there is no other choice. A pod that opted out of preemption will be preempted.
Preemption can never leave a queue lower than its guaranteed capacity
Guaranteed resource capacities configured on a queue are the optimal resources for the queue from a preemption point of view. Since preemption attempts to get a queue at least its guaranteed resources, allowing preemption to reduce a queue below its guaranteed resource capacity would trigger a further round of preemption.
When a task is considered for preemption the removal of the task from the queue's usage must not leave the queue below its guaranteed resource capacity. If the removal of the task would drop the queue below its guarantee that task cannot be a candidate.
This could mean that a queue, even when it is above its guarantee, still does not allow preempting any of the tasks in that queue.
A task cannot preempt other tasks in the same application
As part of the current design we are only implementing inter-queue preemption. This rule does not apply for inter-queue preemption. It is documented here to make extending to intra-queue preemption possible without a rule change.
When a task is considered for preemption the task that triggered the preemption cannot be from the same application.
A task cannot trigger preemption unless its queue is under its guaranteed capacity
Preemption attempts to get a queue at least its guaranteed resources. Allowing preemption for a task in a queue that is already over its guaranteed resource capacity does not help reaching that goal.
Preemption is not the tool to get a queue to its full maximum resource capacity. For that reason no tasks in a queue are allowed to trigger preemption in this case. Normal scheduling will handle the assignment of resources for queues above their guaranteed capacity.
A task cannot be preempted unless its queue is over its guaranteed capacity
This is an extension to the rule that prevents a queue from going below its guaranteed resource capacity. If a queue is already below its guaranteed capacity, no tasks running in that queue can be considered for preemption. The queue can already trigger preemption of tasks from other queues. Allowing preemption to remove more resources from the queue would cause the queue to be even further from its ideal usage.
A task can only preempt a task with lower or equal priority
This rule is linked to the default preemption behavior of Kubernetes. There is however a slight difference when compared to the Kubernetes rule. Kubernetes only allows pods to preempt other pods with a lower priority, not with equal priority.
Preemption in YuniKorn has a slightly broader application as we also use it to allow a queue to use its guaranteed resource capacity. The equality has been added to allow pods from the same priority running in two different queues to preempt each other. Without that equality allowance on priorities that redistribution would be slow and difficult.
A task cannot preempt tasks outside its preemption fence
This last rule is a specific multi-tenancy rule. YuniKorn allows setting up a preemption fence on a queue that will limit the possible tasks that can be considered for preemption. A task can only preempt another task if it runs on a queue that is located inside the preemption fence. More on preemption fencing below.
Preemption Fence
In a cluster that runs workloads for multiple tenants preemption should not be allowed to preempt a workload from one tenant and give the resources to another. A tenant in this case does not have to be a company, it could be a division or business group within the same company. Tenants map to the queue hierarchy. The queue hierarchy can thus cross tenant boundaries.
To translate this to a YuniKorn centric view: confining preemption to assess only a part of the queue hierarchy should be possible. For this we want to introduce a preemption fence. The preemption fence is a setting on the queue which stops preemption from looking at queues outside the fence boundary.
The preemption fence can be set on any queue at any point in the hierarchy. It blocks traversing up the queue hierarchy when looking for a victim to preempt. The fence is a unidirectional fence. It prevents going out (i.e. higher up the queue hierarchy), but does not prevent coming in (or down) the queue hierarchy. The below diagram shows an example hierarchy with preemption fencing applied:
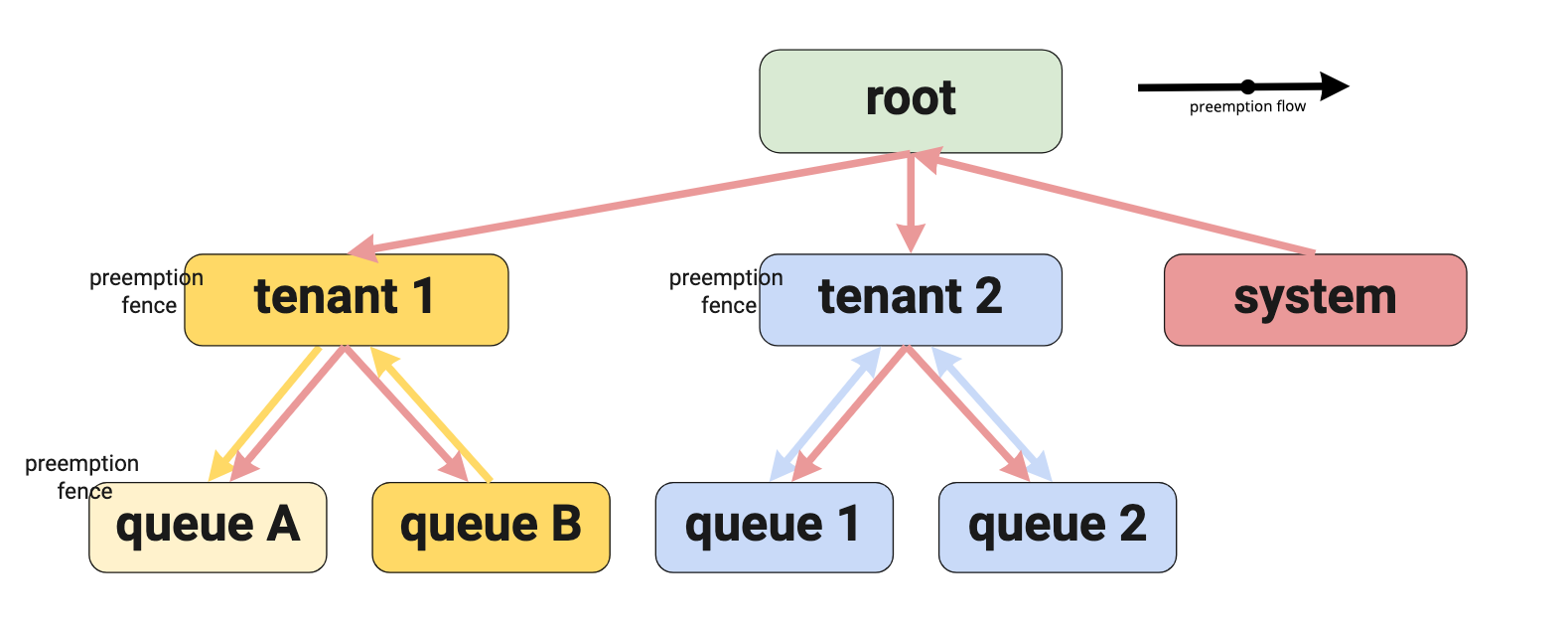
The example has three preemption fences defined at different levels. The arrows describe the preemption flows.
First look at queue A.
A fence is defined on the leaf queue which means that preemption is fenced to
that queue. This would limit tasks to find a preemption victim within the
queue. This in effect turns off inter-queue preemption for the leaf
queue A. This would be a case for intra-queue preemption only. Note that in
the current design intra-queue preemption is excluded, and we will not
implement this use case. However, we do allow the configuration to be set.
The second fence is set up at the tenant 1 level. This fence has an impact
on the task running in queue B. The tasks in queue B can find a victim
to preempt in all queues below the tenant 1 queue (shown in the diagram with
the yellow arrows).
A similar setup is created for the tenant 2 queue. However, in this case
there can be preemption from queue 1 to queue 2 and vice-versa (shown in
the diagram with the blue arrows).
None of the tasks running in the queues below tenant 1 or tenant 2 can
preempt a task from the system queue. Tasks in the system queue are not
fenced. That means that a task in the system queue can check any queue in
the hierarchy (shown in the diagram as the red arrows).
Preemption Logic
For preemption to be triggered by the default Kubernetes scheduler, the pod must fit within any namespace quota and no node can be found to allocate the pod on. Preemption tries to find a node to run the pod on and is focused on nodes only. All pods on a node with a lower priority are considered candidates for preemption. The scheduler reduces the candidates to a victim list just large enough to fit the new pod.
The scheduler tracks the node undergoing preemption in the pod that triggered the preemption. It does not guarantee, for a number of reasons, that the pod that triggered the preemption also gets scheduled on the node the pods were preempted from.
From the YuniKorn side we already have a node focused preemption for DaemonSet pods. A pod from a DaemonSet must run on a specific node. Preemption is focused on making space on that node. YuniKorn guarantees that the pod will run on that node and nothing else will be scheduled on that node until the DaemonSet pod is scheduled.
Generic preemption in YuniKorn is linked to a queue that is under its guaranteed quota (rule 4). The preemption is only triggered after a delay. A request must have been pending for at least the preemption delay before preemption will be considered for it. Instead of looking at a node the first step is to find victims based on the queue that is over its guaranteed quota (rule 5). If no queues can be found within the preemption fence (rule 7), preemption immediately stops.
The next step is to build a list of victims. This could be from one or multiple queues. Any pod with a priority higher (rule 6) than the pod triggering the preemption is discarded. The next step is to discard any pod with resources larger than the over guarantee portion (rule 2). Proximity of the victim queue in the hierarchy to the originating queue that triggers the preemption might be considered when we decide which victims to preempt. Details will be worked out during the implementation phase.
Cross node preemption is not supported. Any set of victims that get preempted must run on the same node. The victims are split into groups per node. A group of victims, combined with the allocatable space on the node, will decide if the group is a viable group. Checks must be run to make sure that the pod will fit the node before starting the preemption. If more than one group is viable a choice will need to be made. The logic for choosing a group is an implementation detail.
After choosing a group and indirectly a node, the node is reserved for the pod. Preemption for the victim list will be triggered and on completion the pod will be scheduled on the node. The reservation guarantees that the pod triggering the preemption will be scheduled on that node. As a side effect the preempted pods that restart can also not “slip back” into the freed up space on the node while the scheduler waits for all preempted pods to exit. They could be scheduled on a different node but not stop the pod that triggered the preemption from being scheduled.
Preemption Loop Prevention
The rules defined prevent looping and circular preemptions. Testing should be added to cover each rule and combinations like below.
ReplicaSets are a good example to look at for looping and circular preemption. Each time a pod from a replica set is removed the ReplicaSet controller will create a new pod to make sure the set is complete. That auto-recreate could trigger loops if the rules are not covering all cases correctly. The case described below should be covered as part of standard testing.
Example setup: Replica set Prod Repl runs in queue Prod. For testing a replica set Test Repl runs in the queue Test. Both queues belong to the same parent queue (they are siblings). The pods all run with the same settings for priority and preemption. There is no space left on the cluster.
Example 1: Prod is under its guaranteed quota and multiple pods of the replica set are pending. All pods for the Test Repl set are running and Test is above its guaranteed resource capacity.
Preemption flow case 1: To make room for a Prod Repl pod, a pod from the Test Repl set is preempted. Both queues will end up above their guaranteed resource. The Test Repl pod is recreated. It cannot preempt the Prod Repl pod as that would leave the Prod queue below its guaranteed resource capacity. The Test Repl pod will have to wait until resources become available in the cluster. The other pods for the Prod Repl set will also have to wait. The Prod queue is now above its guaranteed resource and cannot trigger preemption anymore.
Preemption flow case 2: Test, although above its guaranteed resource capacity, would end up below its guarantee if a pod from Test Repl would be preempted. No preemption happens and the Prod Repl pods will stay pending until space becomes available in the cluster.
Preemption flow case 3: To make room for the Prod Repl pod a pod from the Test Repl set is preempted. The Prod queue, even with the additional pod, is still below its guaranteed resource. The Test Repl pod is recreated. Prod is not considered as a queue with victims as it is still below its guaranteed resources. The Test Repl pod will have to wait until resources become available in the cluster. The Prod queue can trigger further preemptions. Preemption checks start from scratch. Depending on the state this could trigger none or more preemptions from the Test queue.
Preemption Configuration
PriorityClass
As part of the pod specification we need to be able to provide the ability to opt-out of preemption. Allowing a user to specify the opt-out directly on the pod independent of the priority causes a disconnect between Kubernetes and YuniKorn preemption configuration. It also removes control from the administrator of the cluster to define which priorities should not be able to opt out.
One of the goals of the design is to not introduce new objects in Kubernetes. Combined with the above control and management of the opt-out functionality at a cluster level the design reuses the existing PriorityClass object. We cannot and must not break existing functionality of the default Kubernetes scheduler when we do this. The plugin version of Kubernetes relies on the default scheduler and its behavior. Pods will use the priorityClassName just like standard Kubernetes.
The PriorityClass object allows specifying a preemptionPolicy with two possible values:
- PreemptLowerPriority
- Never
The values are hard-coded in the core types and validations. Adding a new value is not possible without making a Kubernetes change. That means we cannot reuse the preemptionPolicy field itself. The content of the field will be propagated to the scheduling core to allow YuniKorn to take the setting into account while scheduling.
Just like all other objects in Kubernetes, the PriorityClass object extends the base object and includes metadata. As part of the metadata we can set labels and or annotations on the object. Labels are more restrictive than annotations. As a generic rule we prefer to use annotations over labels for all the extensions we are adding.
The proposal is to add an annotation to the PriorityClass that allows an
opt-out of preemption. The name of the annotation would follow the same
structure as we use for all other annotations:
yunikorn.apache.org/allow-preemption
As the value of the annotation the proposal is to use a boolean value:
- "true": allow the pod to be preempted,
- "false": do not allow preemption If no value is set for allow-preemption the default value true is used.
The design comes with a caveat. The value of "false" for the annotation on the PriorityClass provides the possibility for a pod to request not to be preempted. However, this is not a guarantee. There could be circumstances that the scheduler might still preempt the pod. This will be a last resort action if no other solution is available. This means that the preemption policy as defined above is a strong suggestion, not a guarantee.
The example use case that could break the rule and preempt a pod with allow-preemption set to false is the DaemonSet case. The DaemonSet pod must run on the specified node. If all pods that are running on that node are either other DaemonSet pods or pods that have allow-preemption set to false there is no other choice. A pod that opted out of preemption will be preempted.
Application Settings
Priority is part of the pod specification on Kubernetes. Every pod is converted into an AllocationAsk by the k8shim. As part of the DaemonSet preemption that was implemented in YUNIKORN-1085 the priority of a pod is read and set on the AllocationAsk that is created. The priority that is passed on currently is just a plain integer value, we do not need more than that.
As part of preemption we need two additional values to be passed on. These two values together form the preemptionPolicy for YuniKorn. The values must be communicated as part of the AllocationAsk sent from the Kubernetes shim to the core. Both values are mapped to the content of the PriorityClass described above. Instead of adding two separate fields, wrapping them into a new message will provide more clarity.
The preemption policy can be processed for any AllocationAsk, even if it has
the Originator flag in the message set to false. Specifying different
preemption behavior for different asks within an application could be important
to allow low-cost asks to be preempted while high-cost asks opt-out.
The use case is again a Spark application. You want the driver pod to opt-out from preemption and, possibly, preempt other pods during scheduling. An executor should do neither.
In protobuf message form that would look like:
message AllocationAsk {
...
// The preemption policy for this ask
PreemptionPolicy preemptionPolicy = 12;
}
message PreemptionPolicy {
// Allow preemption while running
// Based on the YuniKorn annotation from the PriorityClass object
bool allowPreemption = 1;
// Preemption behavior while scheduling
// Based on the K8s preemptionPolicy from the PriorityClass object
string schedulerPreemption = 2;
}
Queue Configuration
Two new attributes will be added to the queue configuration object to allow
specifying the preemption fence type and preemption delay. Both properties,
preemption.policy and preemption.delay, can be set on any queue. The
attributes are part of the queue properties as follows:
queues:
- name: fencedqueue
properties:
preemption.policy: fence
preemption.delay: 30s
Properties are fully supported in child templates. Support for setting these properties for dynamic queues is included as part of the existing functionality.
The preemption.policy property can be set on the root queue but has no effect. The root queue as the top of the hierarchy has no parent. This means preemption cannot traverse further up the tree. No messages will be logged if the preemption.policy is set on the root queue.
The supported values for the preemption.policy are:
- default
- fence
- disabled
If the value fence is set on a queue, tasks running in or below the queue on
which the property is set cannot preempt tasks outside the queue tree. The
value default does not limit preemption to the subtree. If no policy is set
the value default is used.
A preemption.delay can only be set on a leaf queue. The leaf queue contains the tasks. Tasks trigger the preemption in combination with a queue being below its guaranteed resource capacity. Setting a preemption delay on a queue that is not a leaf has no effect. No messages will be logged if a preemption.delay is set on a parent queue.
The preemption.delay value must be a valid Golang duration in string form. The
value will be converted into a duration using ParseDuration as defined in the
time package.
A preemption.delay, if specified, must be larger than 0s. If no
preemption.delay property is specified in the queue the default of 30s is
used. If parsing of the string fails the default of 30s is used.
Scheduler storage object changes
AllocationAsk
In line with the changes for the communication the objects in the scheduler also need to be modified to persist some of the detail communicated. For the AllocationAsk we need to store both new fields.
Proposed new fields: allowPreemption and schedulerPreemption
- schedulerPreemption is only used during the scheduling phase.
- allowPreemption will be propagated to the resulting allocation as defined below.
Allocation
The allocation that gets created based on the AllocationAsk needs a new field. This removes the need to check the underlying AllocationAsk if it allows preemption or not. The scheduler preemption value is not required in the Allocation.
Proposed new field: allowPreemption
Queue
The new preemption policy and delay values will need to be stored in the Queue object. The configuration object does not change as we use the properties of the Queue in the configuration to store them.
Proposed new fields: preemptionPolicy and preemptionDelay